Video Deblurring by Fitting to Test Data
Xuanchi Ren*, Zian Qian* , Qifeng Chen
* indicates equal contribution
Abstract
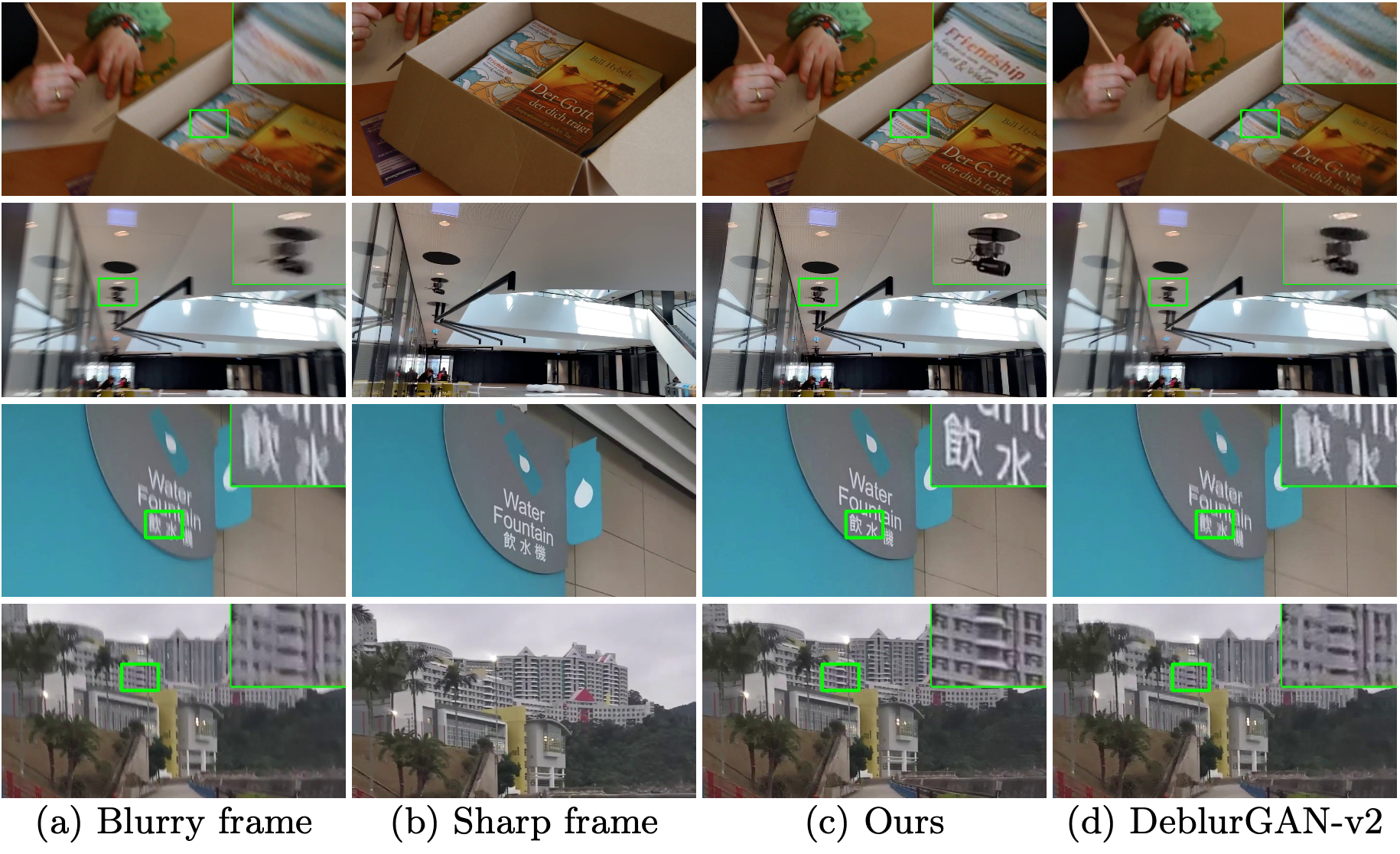
We present a novel approach to video deblurring without training data by fitting a deep network to the test video. One key observation is that some frames in a video with motion blur are much sharper than others, and thus we can transfer the information in those sharp frames into blurry frames. We heuristically select sharp frames from a video and then train a convolutional network on these sharp frames. The trained network often absorbs enough details in the scene to perform deblurring on all the video frames. Our approach has no domain gap between training and test set, which is a problematic issue for existing video deblurring approaches. In the experiments, we show that our model can reconstruct clearer and sharper videos than state-of-the-art methods on real-world data.
Downloads
Citation
@inproceedings{FTTD,
title={Video Deblurring by Fitting to Test Data},
author={},
booktitle={},
year={2020}
}
Motivation
Recovering sharp frames from a blurry video is still challenging for learning-based methods due to the domain gap between training and testing data. For example, a model trained on a dataset captured in a library may have bad performance when tested on daily videos captured in a supermarket. Moreover, since it is hard to capture the ground truth corresponding to the daily blurry video, researchers synthesize blurry videos instead of directly using real blurry videos during training. However, the real motion blur is different from synthetic blur. The model trained on synthetic data in a different scenario fails to handle the motion blur in a daily video. Therefore, the state-of-the-art video deblurring methods often produce poor results on real-scene videos.
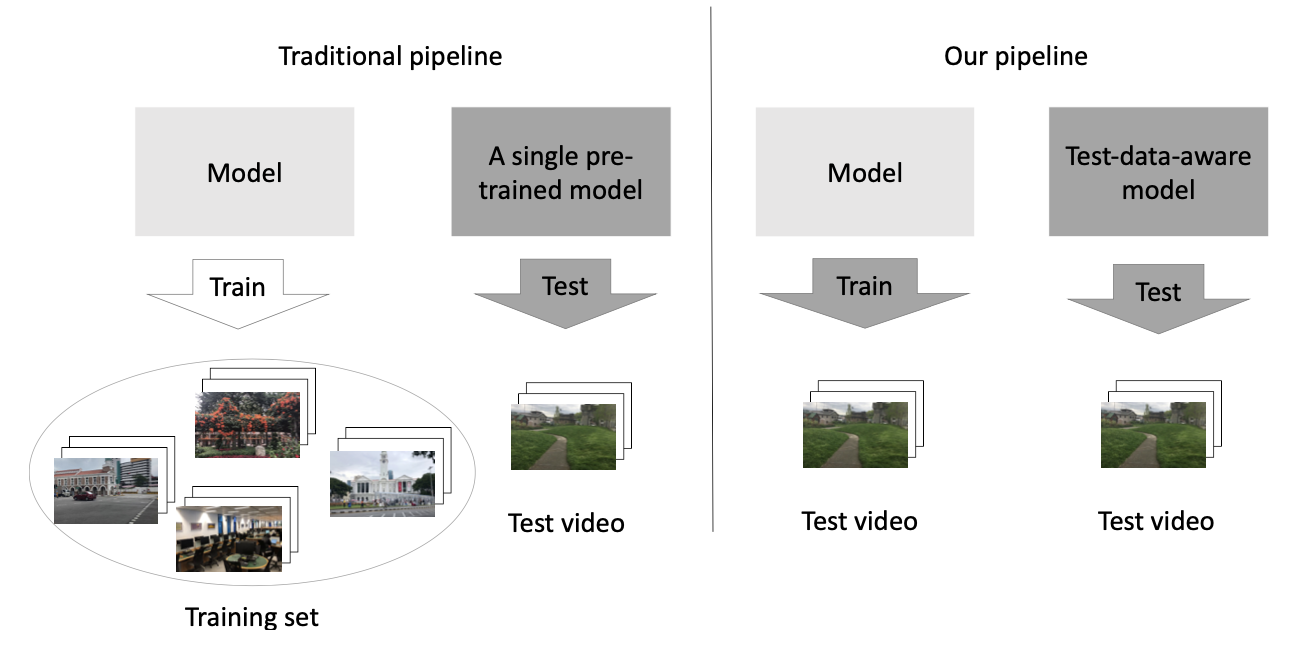
To address the domain gap problem, we introduce a self-supervised pipeline by fitting a deep learning model only on the test video. Unlike traditional supervised pipeline, our method does not rely on training on a large (synthetic) dataset. Our approach is built upon an observation that some frames in a video with motion blur are extremely sharp and clear. Based on this crucial observation, we exploit the internal information of a video by training a simple but efficient convolutional network (CNN) on the sharp-blurry patch pairs generated by our blur generation strategy. As such, our test-data-aware CNN model can adapt to any scenarios and settings of daily videos without the domain gap between training and test data. We also improve our training process with better initialization using MAML, which successfully reduces the running time for a video from hours to 5 minutes.
Proposed Algorithm
Comparison between the traditional pipeline and our pipeline for video deblurring:
Fitting-to-Test-data Pipeline
Given a video, we first perform sharp frame selection. Then, we repeatedly and randomly crop patches from these sharp frames and apply a blur generation method on these patches to obtain the corresponding blur patches to train a network. After fitting these sharp frames, the network is fed in all the video frames to refine them.
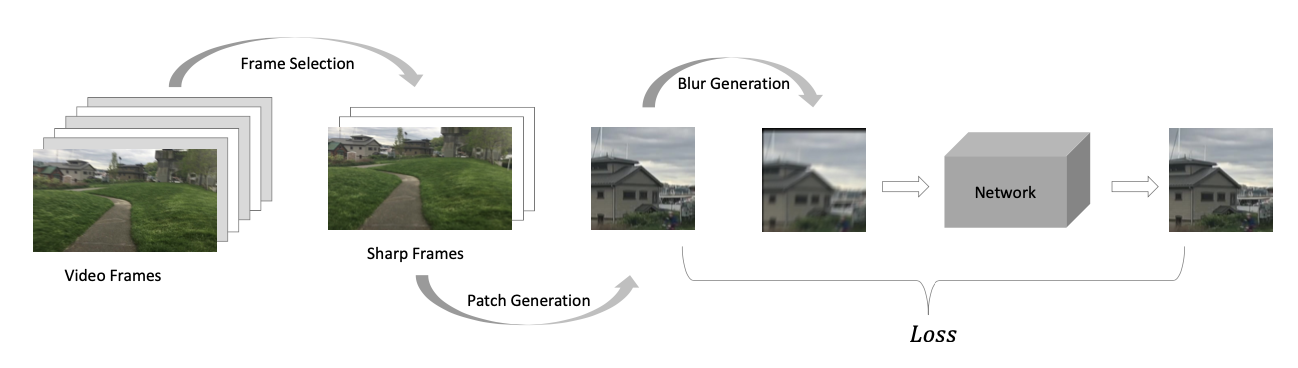
Accelerated Pipeline
Our pipeline exploits the internal information of sharp frames in the test video. However, it usually takes hours to fit a model to these sharp frames for video deblurring due to the complexity and a massive number of possible blur kernels. In our experiments, we notice that the network takes a long period to adapt itself to generate expected sharp images at the beginning of the training. We propose to initialize the network via meta-learning, which enables rapid fitting on any given video at test time.

Dataset
In prior video deblurring work, synthetic datasets are often used for evaluation because there are no ground-truth sharp videos for real-world blurry videos. However, we should better evaluate different methods on real-world blurry videos rather than synthetic data. We find that a model training on synthetic data does not necessarily perform well on real-world data. Therefore, we collect a real-world video dataset with 70 videos with motion blur for qualitative and quantitative evaluation. The videos are captured by shaking, walking, or running in diverse indoor and outdoor environments. Each video contains 80-160 frames, shot with iPhone 8 Plus, iPhone 11 Pro Max, or Huawei Mate 20. Although there are no ground-truth sharp videos in our dataset, we can still conduct a user study to compare different methods quantitatively.
Experimental Results
Quantitative evaluations on the video deblurring dataset by user study.

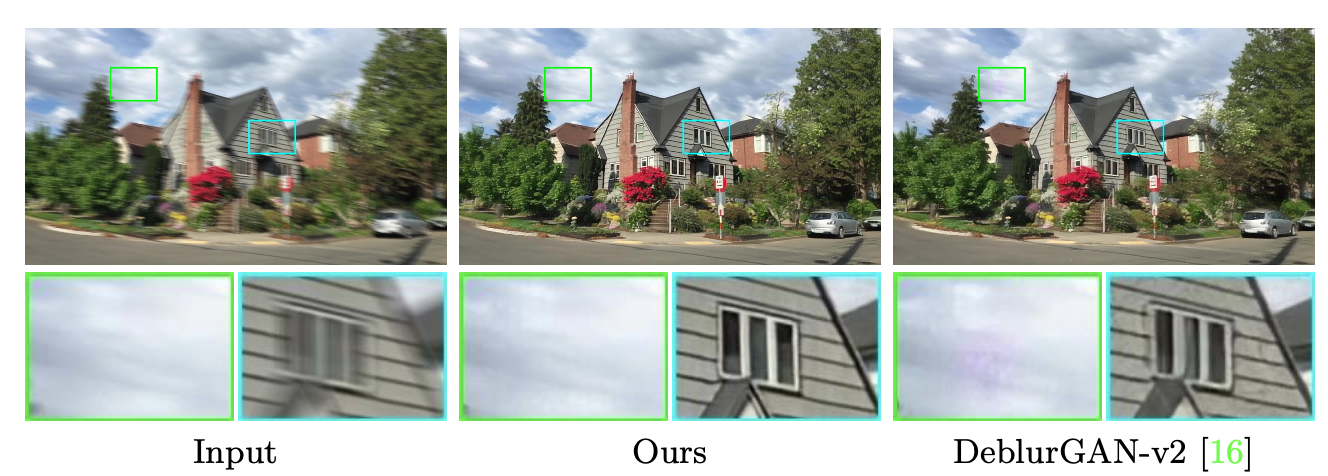
Visual comparisons on our real-world video deblurring dataset. Ours is from our fitting-to-test-data pipeline, and our MAML is from our accelerated pipeline. Our method is capable of restoring the text information.

Contact
If you have any question, please contact us at:
- E-mail: xrenaa@connect.ust.hk